Case studies


















AI-Powered Entity Resolution Pipeline for Unstructured Financial Documents
An AI pipeline that links unstructured company presentations to a structured company database. It reads text even from scanned, image-only PDFs, keeps language model cost flat no matter how long a document is, and matches company identity when the two datasets share no common field. The target was a match rate of at least 85 percent.

Project Background
A financial data and market intelligence provider had spent years building two valuable datasets. Each dataset was useful on its own, but their real value came from connecting them.
The first dataset was an Amazon S3 bucket containing company presentations stored as PDFs. It included investor decks, company overviews, and profiles of public and private companies. The second dataset was a structured company database. Each record contained a primary company name, an alternative name, a three-level GICS industry classification, and a location.
When used separately, both datasets had limitations. The presentations contained detailed company information, but they were not connected to the company database. The database was clean, structured, and searchable, but it had no direct links to the documents that provided additional context. The missing piece was a reliable connection between the two datasets. Nothing inside a PDF clearly identified which company record it belonged to.
This pipeline was built to create that connection across thousands of inconsistent presentations.
Once every presentation is linked to a company record, the archive becomes much more useful. Analysts can move directly from a company record to its supporting documents. Documents can also be viewed within the broader company landscape instead of on their own. The archive is no longer just a collection of stored files. It becomes a searchable source of business intelligence.
The Challenge
The goal was to join two datasets. The challenge was that the datasets had no shared field that could be used for matching. To connect them, each document had to be opened, the company behind it had to be identified, and the correct company record had to be found in the database. Each step created challenges for automation.
Many PDFs had no extractable text. Some files were scanned documents. Others had been exported as flat images. In these cases, standard text extraction returned nothing. Any workflow that depended on clean and selectable text would fail on a significant part of the archive.
The documents were also too large for naive processing. Many presentations contained more than 100 pages. Sending documents of that size to a language model was technically possible, but doing it for every file in a large and constantly growing archive would be slow and expensive. A full archive scan using this approach was not economically practical.
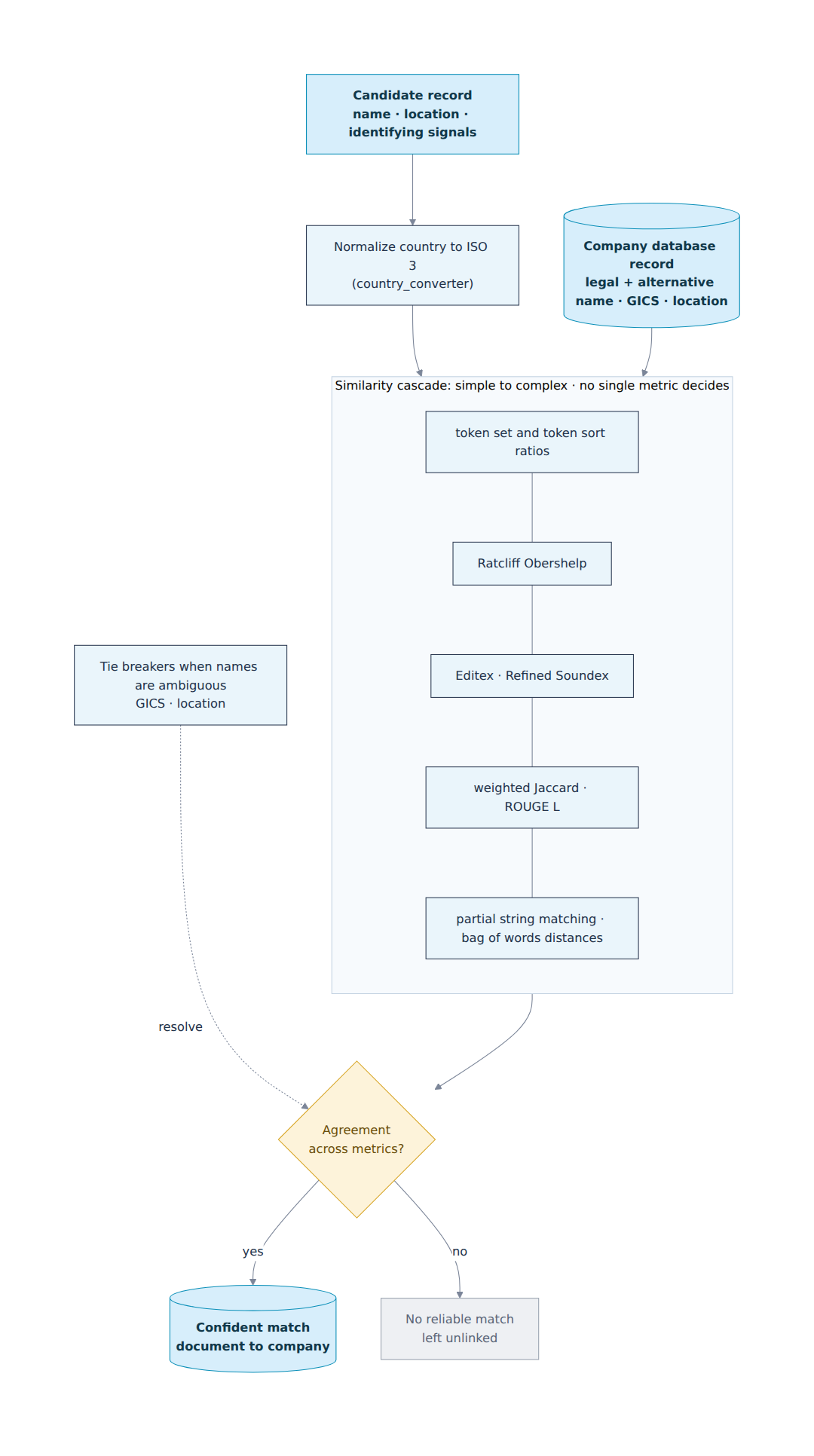
Matching company names created another problem. Names rarely appeared in the same form across both datasets. A presentation might use a trading name, a former name, a local name, or an abbreviation. The database usually contained a legal name and one alternative name. Location data and GICS classification helped narrow down the options, but the datasets had no shared identifier. There was also no single matching method that worked reliably across all name variations.
The project had a clear performance target. The system needed to achieve a match rate of at least 85 percent. At that level, the linked dataset would be reliable enough to support further analysis and development.
The Solution
We designed the solution as a four-stage pipeline. The stages covered ingestion, text extraction, data preparation, and data extraction. The output then moved into a final matching step based on multiple metrics. Two core principles guided the design.
The first principle was a clear separation between language model tasks and deterministic logic. Extracting company information from messy and inconsistent documents was a good fit for a language model. It could handle ambiguity, different writing styles, and missing structure better than rule-based parsing. Matching records and confirming that they referred to the same company required a different approach. That step relied on deterministic logic and explicit validation. The same inputs always produced the same result, and every match could be reviewed and explained.
Language models handled ambiguity and information extraction. Deterministic matching and validation provided reliability.
The second principle was cost control. Each stage used the simplest and least expensive method that could solve the problem. More expensive processing was used only when necessary. Results were cached so the same work did not need to be repeated. In document processing, a system can produce accurate results and still be too expensive to operate. In this pipeline, cost was treated as a design requirement from the beginning.
How the Pipeline Works
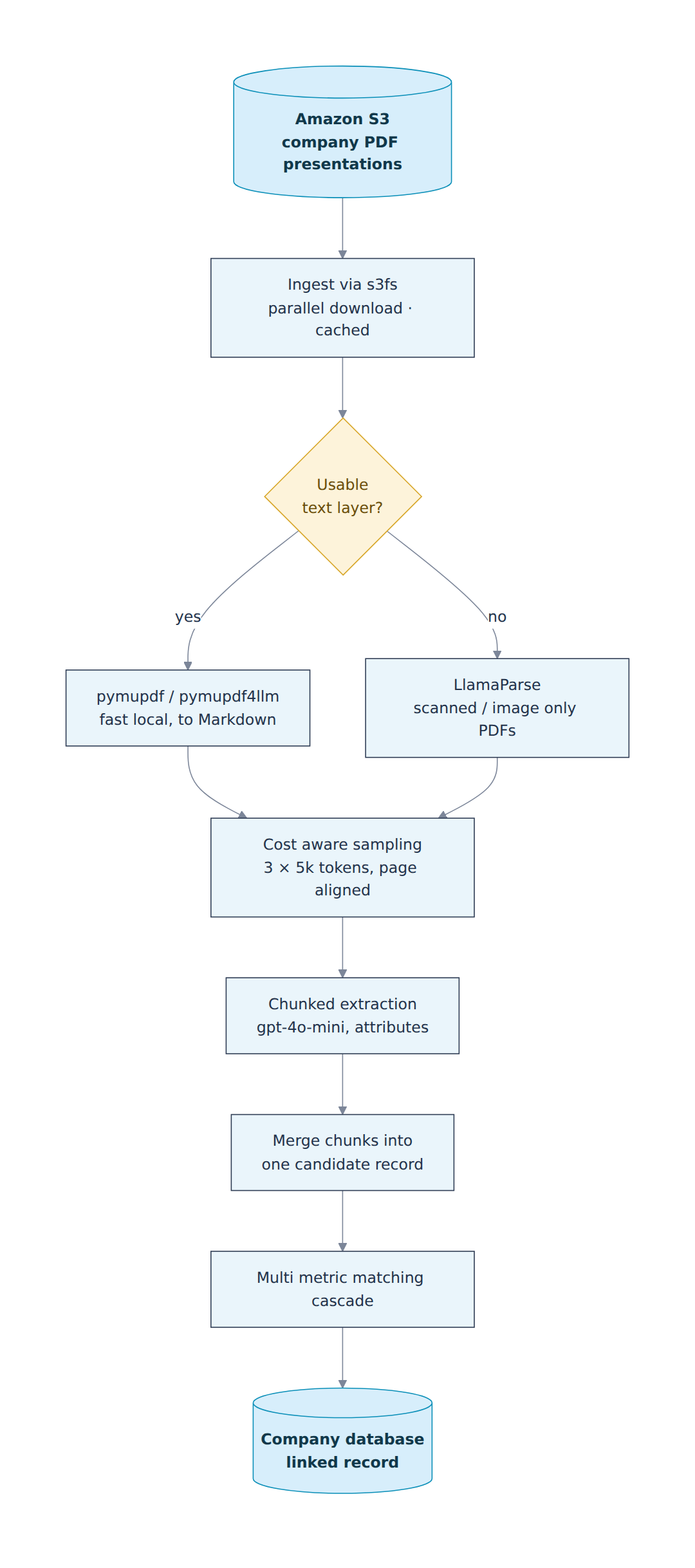
Resilient document ingestion. The system begins by connecting to the S3 bucket through s3fs, which exposes it as a local filesystem. This allows the code to treat remote files as if they were stored locally. Downloads run in parallel using multiple worker threads. This makes throughput depend on bandwidth rather than on sequential network requests. Every file is cached locally after the first download. After that, any rerun, whether during development or after a logic change, uses the local cache and does not hit the network. For an archive of this size, this turns repeated downloads into a one time cost.
Cascading text extraction. Many PDFs do not contain a usable text layer. Because of this, extraction is designed as a fallback chain instead of a single step. The pipeline first uses fast local extraction with pymupdf and pymupdf4llm. This converts documents into Markdown style text that is easier to process later. If this produces no usable result, the file is passed to LlamaParse. This is a heavier parsing service that handles scanned pages, images, and complex layouts. The order is intentional. The fast method handles most files, and the slower method is used only when needed. This keeps extraction coverage high while controlling cost.
Cost aware sampling. A 100 page presentation does not need to be fully read to identify the company behind it. The key information is usually in the first pages and the last pages. The pipeline samples about 5,000 tokens from the beginning, 5,000 from the middle, and 5,000 from the end. It always cuts on full page boundaries so no page is split. This creates a fixed cost per document. A long deck and a short deck cost the same to process. The total archive size does not increase processing cost in a linear way.
Chunked extraction. The sampled text is split into chunks that fit within the model context window. Each chunk is sent to gpt-4o-mini. The model extracts structured company attributes such as name, location, and identifying signals. Splitting the input keeps each call within safe limits and makes the system stable for large or dense documents. The results from all chunks are then merged into a single candidate record. Overlapping or partial information is combined into one consistent view of the company.
Multi metric matching. The candidate record is then matched against the company database. Because there is no shared identifier, the system uses multiple similarity methods instead of a single one. The matching cascade includes token set and token sort ratios, Ratcliff Obershelp, Editex, Refined Soundex, weighted Jaccard, ROUGE L, partial string matching, and bag of words distances. Each method handles different types of variation. Some are better at word order changes. Some are better at spelling differences or missing tokens. Country names are normalized to ISO 3 codes using country_converter so formatting does not affect matching. GICS classification and location are used as additional signals when names are ambiguous. No single metric decides the result. Matches are based on agreement across multiple methods, which makes the final output more reliable.
Architecture
The pipeline is built end to end in Python, chosen less for raw speed than for the breadth of its data and document-processing ecosystem. Nearly every component, from S3 access to PDF parsing to string matching, exists as a mature, well-supported library.
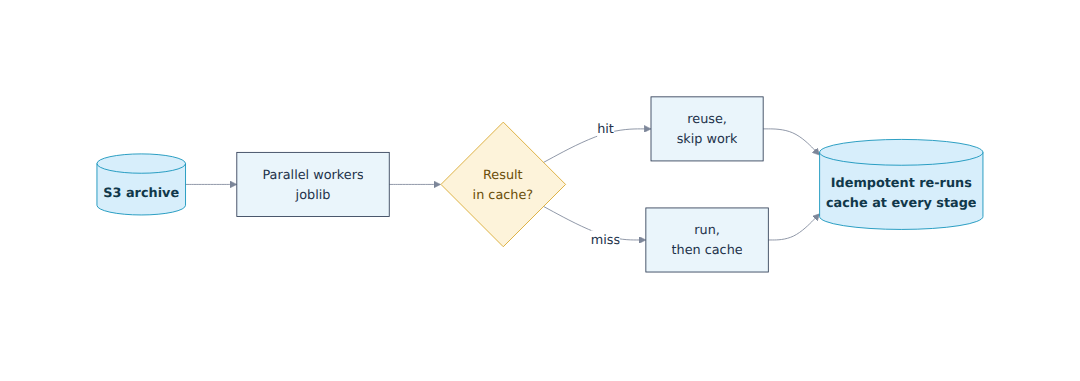
Polars handles all of the tabular work, the company database and every intermediate dataset, with a dataframe model that stays fast and memory efficient as the data grows. joblib runs the heavy stages, which parallelise cleanly across workers, so ingestion and extraction scale with available cores rather than processing one document at a time.
The defining architectural decision is caching at every boundary. Downloaded files, extracted Markdown, and prepared text are all saved as they are produced. This makes the whole pipeline repeat-safe: a re-run never repeats work that has already succeeded, only work that has not. During development this turns a multi-hour pass into a fast feedback loop. In production it keeps re-processing a continuously growing archive inexpensive. Every stage is protected by its own cache check.
Technology Stack
- Language and data: Python as the implementation language; Polars for fast, memory efficient tabular data; s3fs to mount Amazon S3 as a filesystem.
- PDF extraction: pymupdf and pymupdf4llm for fast local PDF to Markdown conversion; LlamaParse as the fallback for scanned and image based documents.
- AI extraction: gpt-4o-mini for structured extraction of company attributes from document text.
- Parallelism: joblib for running the heavy stages across multiple workers.
- Normalization: country_converter for resolving country names to consistent ISO 3 codes.
- Matching: fuzzywuzzy, python-Levenshtein, and name_matching for the cascade of string similarity metrics.
Outcomes
In test runs on representative document batches, the pipeline extracted company identity and produced matches in line with the project's 85 percent target, holding up against real, messy documents rather than curated examples. The more durable outcomes are in the engineering:
- Every PDF in the archive becomes processable; image only and scanned files no longer fall silently out of the dataset.
- Processing cost scales with the number of documents, not their combined page count, so the budget stays predictable as the archive grows.
- Ambiguous, mismatched company names resolve into confident links, because no single metric has to be right on its own.
- A continuously growing archive can be re-processed at near zero marginal cost, thanks to caching at every stage.
- Each stage (ingestion, extraction, matching) is independent and swappable, so the pipeline adapts instead of being rebuilt.
Together these turn an opaque pile of PDFs into the linked, queryable data a searchable intelligence layer is built from.
Summary
The problem started with two datasets that were never designed to work together. One held thousands of company presentations stored as PDFs. The other was a structured database of company records. There was no shared identifier between them, which made any direct connection impossible.
The pipeline was built to close that gap. It turns unstructured documents into structured company signals, and then connects those signals to the database using multiple layers of matching. Along the way, it deals with missing text layers, inconsistent naming, large file sizes, and strict cost constraints.
As the system runs through the archive, each document is processed only as much as needed. Files are downloaded once, extracted through a fallback chain, and sampled instead of fully read. Company information is extracted in chunks, then merged into a single record. Matching is not based on a single rule, but on agreement across multiple signals.
What was once a static collection of PDFs becomes a connected layer of company data. Analysts can move from a company record directly into its supporting documents. The archive stops being storage and starts behaving like a system that can be searched, explored, and used.
Try us for 14 days
Want to start a 2-week free trial period with us? Leave your email below and we'll revert to you shortly with more details